It's been nearly half a century since cron was first introduced, and now we have a handful orchestration tools that go way beyond just scheduling tasks. With data folks constantly debating about which tools are top-notch and which ones should leave the scene, it's like we're at a turning point in the evolution of these tools. By that I mean the term 'orchestrator' has become kind of a catch-all, and that's causing some confusion because we're using this one word to talk about a bunch of different things.

Think about the word “date.” It can mean a fruit, a romantic outing, or a day on the calendar, right? We usually figure out which one it is from the context, but what does context mean when it comes to orchestration? It might sound like a simple question, but it's pretty important to get this straight.
And here's a funny thing: some people, after eating an odd-tasting date (the fruit, of course), are so put off that they naively swear off going on romantic dates altogether. It's an overly exaggerated figurative way of looking at it, but it shows how one bad experience can color our view of something completely different. That's kind of what's happening with orchestration tools. If someone had a bad time with one tool, they might be overly critical towards another, even though it might be a totally different experience.
So the context in terms of orchestration tools seems to be primarily defined by one thing - WHEN a specific tool was first introduced to the market (aside from the obvious factors like the technical background of the person discussing these tools and their tendency to be a chronic complainer 🙄).
IT'S ALL ABOUT TIMING!
The Illegitimate Child
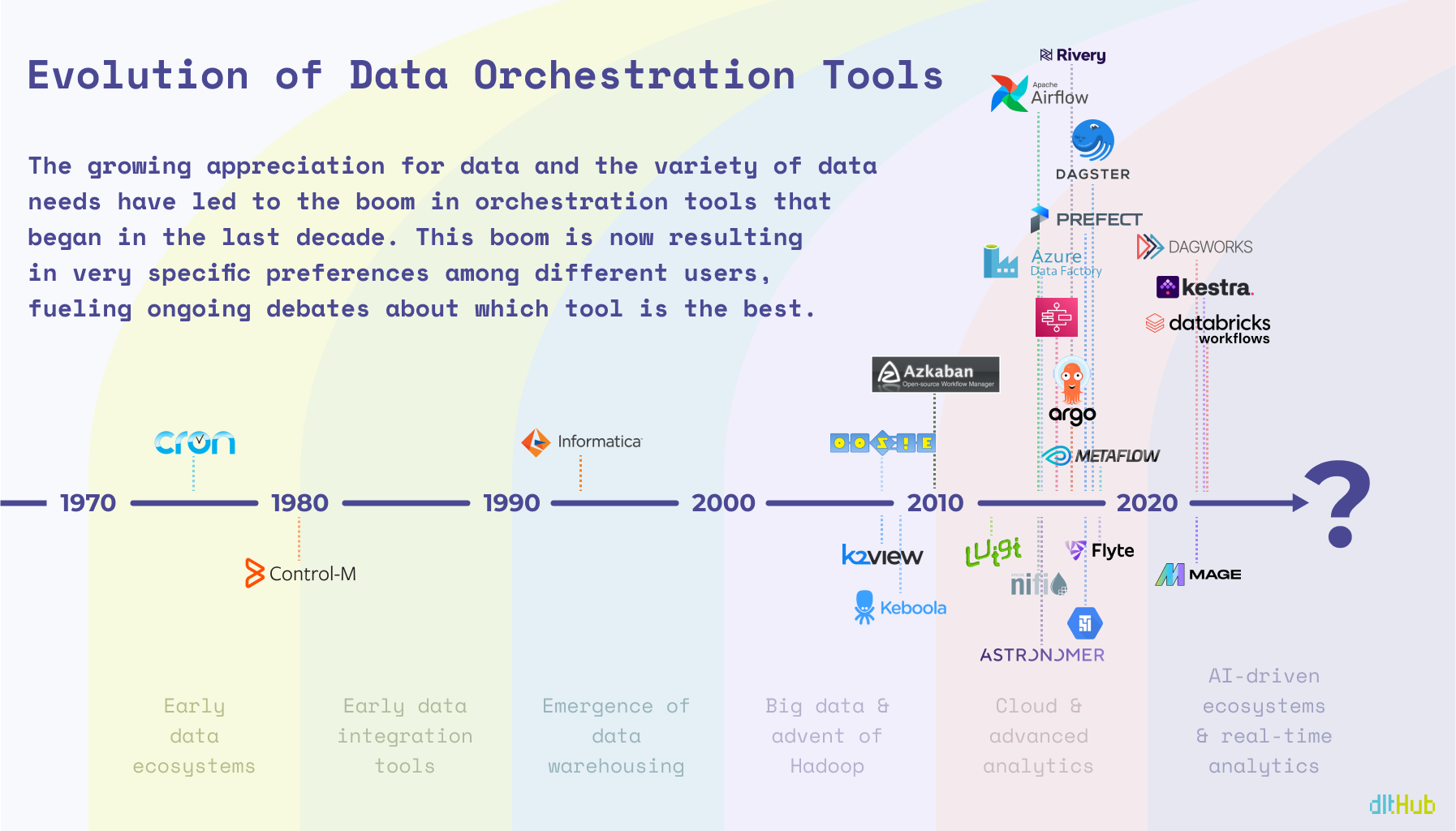
Cron was initially released in 1975 and is undoubtedly the father of all scheduling tools, including orchestrators, but I’m assuming Cron didn’t anticipate this many offspring in the field of data (or perhaps it did). As Oracle brought the first commercial relational database to market in 1979, people started to realize that data needs to be moved on schedule, and without manual effort. And it was doable, with the help of Control-M, though it was more of a general workflow automation tool that didn’t pay special attention to data workflows.
Basically, since the solutions weren’t data driven at that time, it was more “The job gets done, but without a guarantee of data quality.”
Finally Adopted
Unlike Control-M, Informatica was designed for data operations in mind from the beginning. As data started to spread across entire companies, advanced OLAPs started to emerge with a broad use of datawarehousing. Now data not only needed to be moved, but integrated across many systems and users. The data orchestration solution from Informatica was inevitably influenced by the rising popularity of the contemporary drag-and-drop concept, that is, to the detriment of many modern data engineers who would recommend to skip Informatica and other GUI based ETL tools that offer ‘visual programming’.
As the creator of Airflow, Max Beauchemin, said: “There's a multitude of reasons why complex pieces of software are not developed using drag and drop tools: it's that ultimately code is the best abstraction there is for software.”
To Be Free, That Is, Diverse
With traditional ETL tools, such as IBM DataStage and Talend, becoming well-established in the 1990s and early 2000s, the big data movement started gaining its momentum with Hadoop as the main star. Oozie, later made open-source in 2011, was tasked with workflow scheduling of Hadoop jobs, with closed-source solutions, like K2View starting to operate behind the curtains.
Fast forward a bit, and the scene exploded, with Airflow quickly becoming the heavyweight champ, while every big data service out there began rolling out their own orchestrators. This burst brought diversity, but with diversity came a maze of complexity. All of a sudden, there’s an orchestrator for everyone — whether you’re chasing features or just trying to make your budget work 👀 — picking the perfect one for your needs has gotten even trickier.

The Bottom Line
The thing is that every tool out there has some inconvenient truths, and real question isn't about escaping the headache — it's about choosing your type of headache. Hence, the endless sea of “versus” articles, blog posts, and guides trying to help you pick your personal battle.
A Redditor: “Everyone has hated all orchestration tools for all time. People just hated Airflow less and it took off.“
What I'm getting at is this: we're all a bit biased by the "law of the instrument." You know, the whole “If all you have is a hammer, everything looks like a nail” thing. Most engineers probably grabbed the latest or most hyped tool when they first dipped their toes into data orchestration and have stuck with it ever since. Sure, Airflow is the belle of the ball for the community, but there's a whole lineup of contenders vying for the spotlight.

And there are obviously those who would relate to the following:

A HANDY DETOUR POUR TOI 💐
The Fundamentals
- A Brief History of Workflow Orchestration by Prefect.
- What is Data Orchestration and why is it misunderstood? by Hugo Lu.
- The evolution of data orchestration: Part 1 - the past and present by Jonathan Neo.
- The evolution of data orchestration: Part 2 - the future by Jonathan Neo.
- Bash-Script vs. Stored Procedure vs. Traditional ETL Tools vs. Python-Script by Simon Späti.
About Airflow
- 6 inconvenient truths about Apache Airflow (and what to do about them) by IBM.
- Airflow Survey 2022 by Airflow.
Miscellaneous
- Picking A Kubernetes Orchestrator: Airflow, Argo, and Prefect by Ian McGraw.
- Airflow, Prefect, and Dagster: An Inside Look by Pedram Navid.
WHAT THE FUTURE HOLDS...
I'm no oracle or tech guru, but it's pretty obvious that at their core, most data orchestration tools are pretty similar. They're like building blocks that can be put together in different ways—some features come, some go, and users are always learning something new or dropping something old. So, what's really going to make a difference down the line is NOT just about having the coolest features. It's more about having a strong community that's all in on making the product better, a welcoming onboarding process that doesn't feel like rocket science, and finding that sweet spot between making things simple to use and letting users tweak things just the way they like.
In other words, it's not just about what the tools can do, but how people feel about using them, learning them, contributing to them, and obviously how much they spend to maintain them. That's likely where the future winners in the data orchestration game will stand out. But don’t get me wrong, features are important — it's just that there are other things equally important.
SO WHO'S ACTUALLY TRENDING?
I’ve been working on this article for a WHILE now, and, honestly, it's been a bit of a headache trying to gather any solid, objective info on which data orchestration tool tops the charts. The more I think about it, the more I realise it's probably because trying to measure "the best" or "most popular" is a bit like trying to catch smoke with your bare hands — pretty subjective by nature. Plus, only testing them with non-production level data probably wasn't my brightest move.
However, I did create a fun little project where I analysed the sentiment of comments on articles about selected data orchestrators on Hacker News and gathered Google Trends data for the past year.
Just a heads-up, though: the results are BY NO MEANS reliable and are skewed due to some fun with words. For instance, searching for “Prefect” kept leading me to articles about Japanese prefectures, “Keboola” resulted in Kool-Aid content, and “Luigi”... well, let’s just say I ran into Mario’s brother more than once 😂.
THE FUN LITTLE PROJECT
Straight to the GitHub repo.
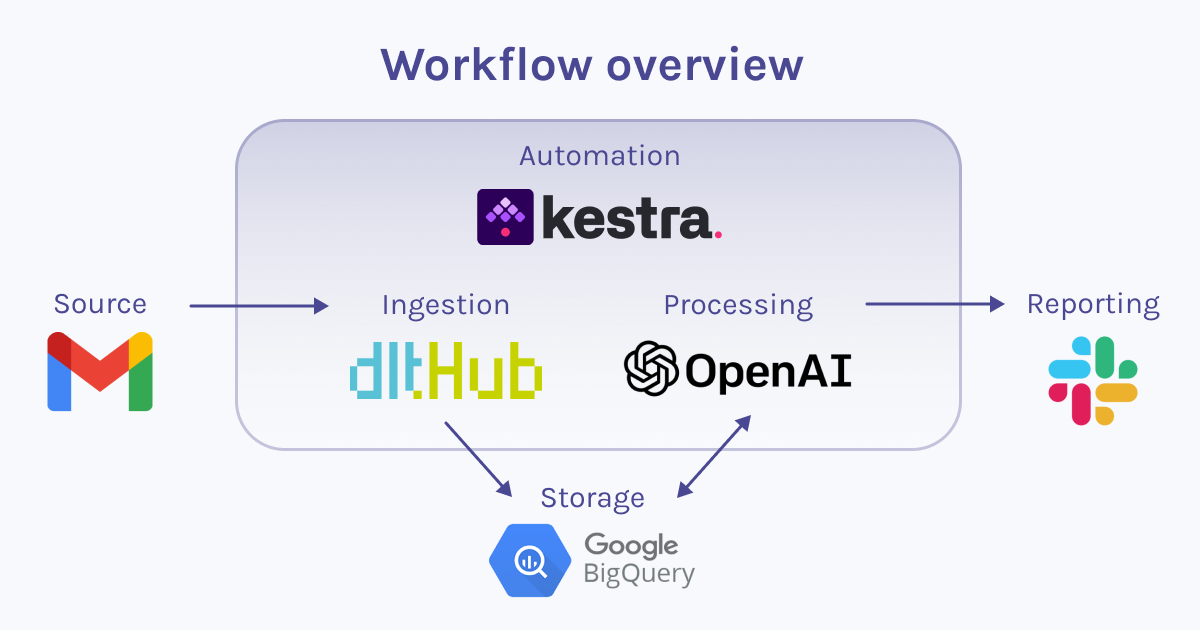
I used Dagster and dlt to load data into Snowflake, and since both of them have integrations with Snowflake, it was easy to set things up and have them all running:
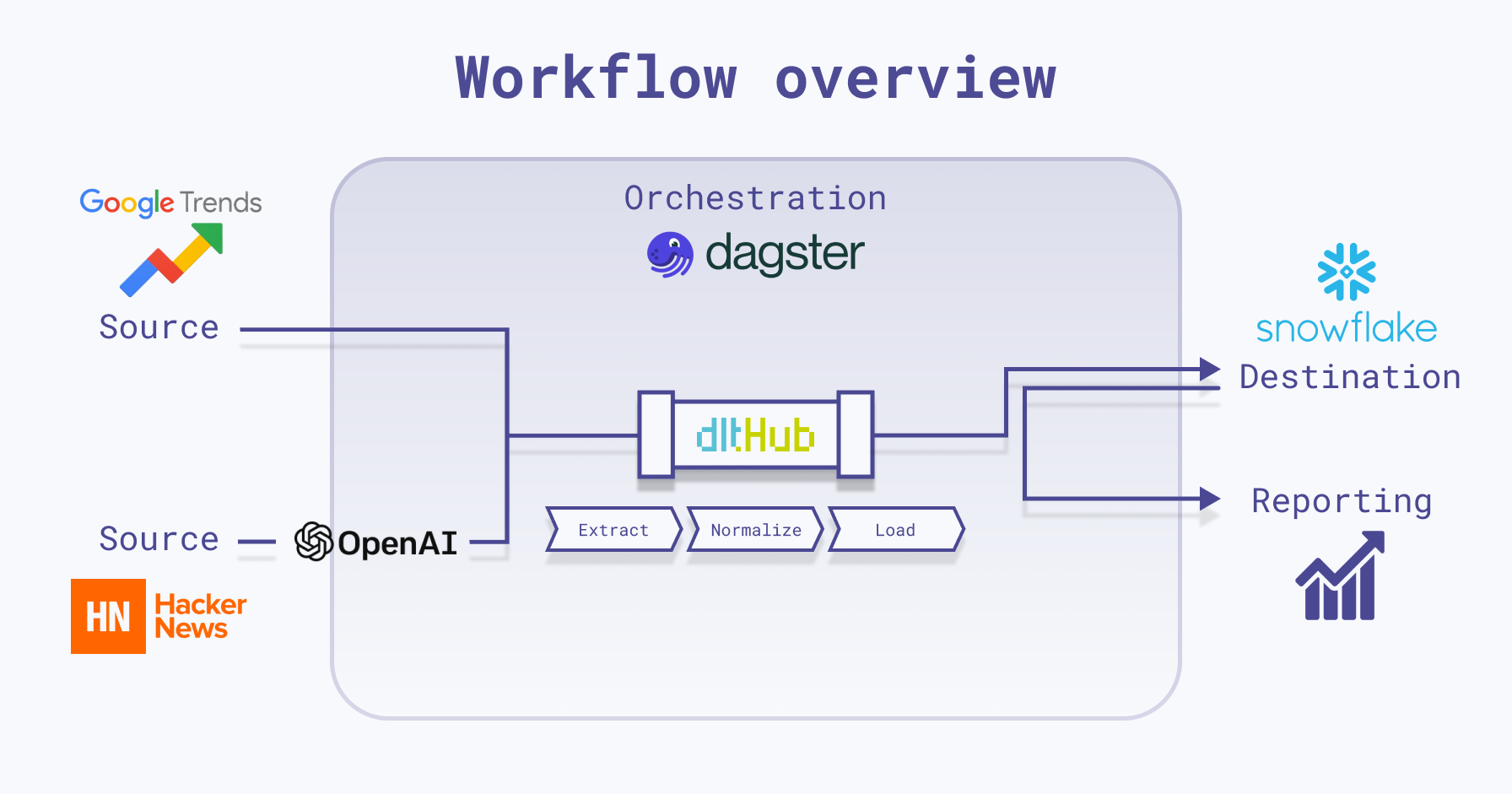
This project is very minimal, including just what's needed to run Dagster locally with dlt. Here's a quick breakdown of the repo’s structure:
.dlt: Utilized by thedltlibrary for storing configuration and sensitive information. The Dagster project is set up to fetch secret values from this directory as well.charts: Used to store chart images generated by assets.dlt_dagster_snowflake_demo: Your Dagster package, comprising Dagster assets,dltresources, Dagster resources, and general project configurations.
Dagster Resources Explained
In the resources folder, the following two Dagster resources are defined as classes:
DltPipeline: This is ourdltobject defined as a Dagster ConfigurableResource that creates and runs adltpipeline with the specified data and table name. It will later be used in our Dagster assets to load data into Snowflake.class DltPipeline(ConfigurableResource):
# Initialize resource with pipeline details
pipeline_name: str
dataset_name: str
destination: str
def create_pipeline(self, resource_data, table_name):
"""
Creates and runs a dlt pipeline with specified data and table name.
Args:
resource_data: The data to be processed by the pipeline.
table_name: The name of the table where data will be loaded.
Returns:
The result of the pipeline execution.
"""
# Configure the dlt pipeline with your destination details
pipeline = dlt.pipeline(
pipeline_name=self.pipeline_name,
destination=self.destination,
dataset_name=self.dataset_name
)
# Run the pipeline with your parameters
load_info = pipeline.run(resource_data, table_name=table_name)
return load_infoLocalFileStorage: Manages the local file storage, ensuring the storage directory exists and allowing data to be written to files within it. It will be later used in our Dagster assets to save images into thechartsfolder.
dlt Explained
In the dlt folder within dlt_dagster_snowflake_demo, necessary dlt resources and sources are defined. Below is a visual representation illustrating the functionality of dlt:
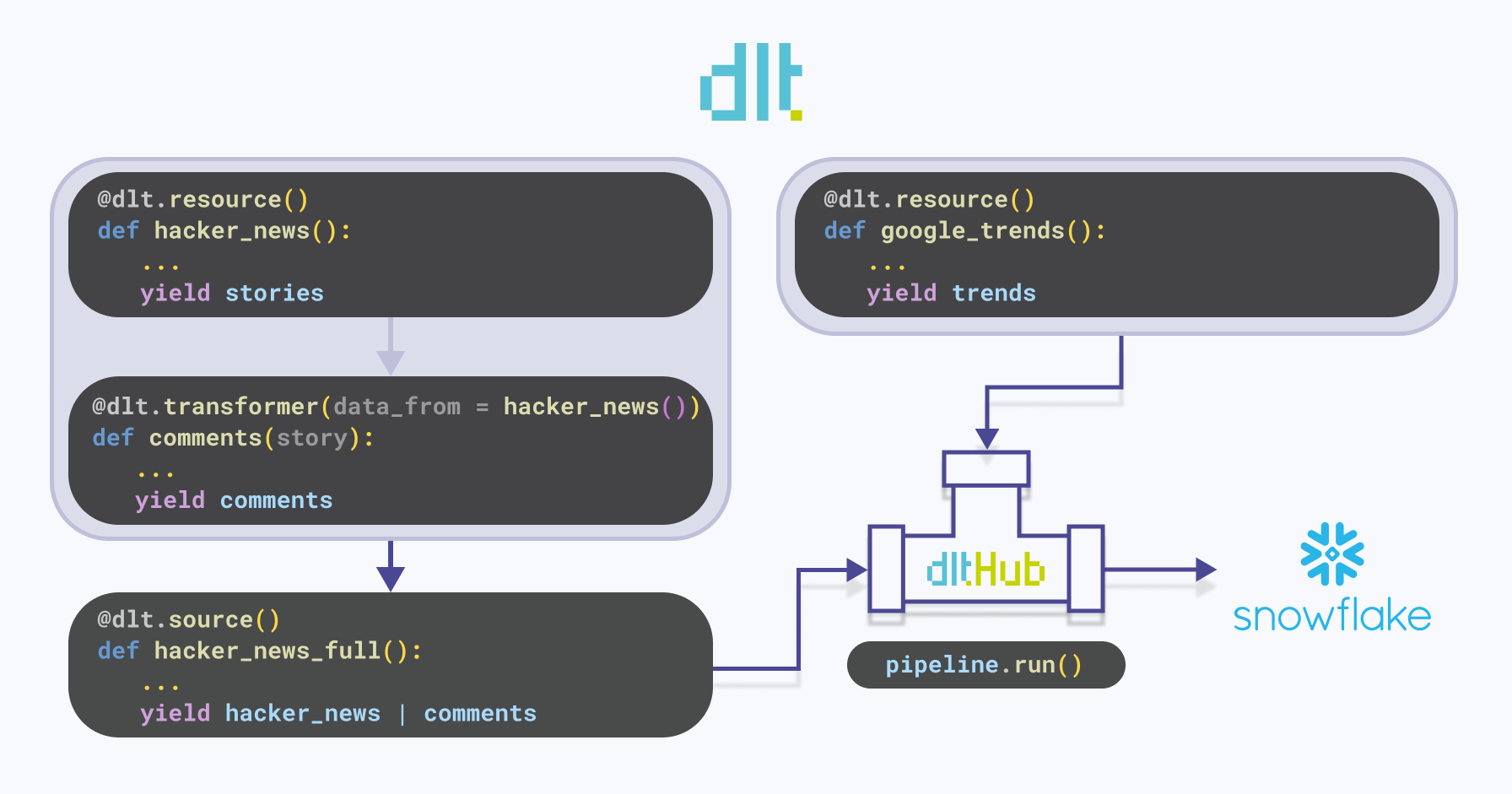
hacker_news: Adltresource that yields stories related to specified orchestration tools from Hackernews. For each tool, it retrieves the top 5 stories that have at least one comment. The stories are then appended to the existing data.Note that the
write_dispositioncan also be set tomergeorreplace:- The merge write disposition merges the new data from the resource with the existing data at the destination. It requires a
primary_keyto be specified for the resource. More details can be found here. - The replace write disposition replaces the data in the destination with the data from the resource. It deletes all the classes and objects and recreates the schema before loading the data.
More details can be found here.
- The merge write disposition merges the new data from the resource with the existing data at the destination. It requires a
comments: Adlttransformer - a resource that receives data from another resource. It fetches comments for each story yielded by thehacker_newsfunction.hacker_news_full: Adltsource that extracts data from the source location using one or more resource components, such ashacker_newsandcomments. To illustrate, if the source is a database, a resource corresponds to a table within that database.google_trends: Adltresource that fetches Google Trends data for specified orchestration tools. It attempts to retrieve the data multiple times in case of failures or empty responses. The retrieved data is then appended to the existing data.
As you may have noticed, the dlt library is designed to handle the unnesting of data internally. When you retrieve data from APIs like Hacker News or Google Trends, dlt automatically unpacks the nested structures into relational tables, creating and linking child and parent tables. This is achieved through unique identifiers (_dlt_id and _dlt_parent_id) that link child tables to specific rows in the parent table. However, it's important to note that you have control over how this unnesting is done.
The Results
Alright, so once you've got your Dagster assets all materialized and data loaded into Snowflake, let's take a peek at what you might see:
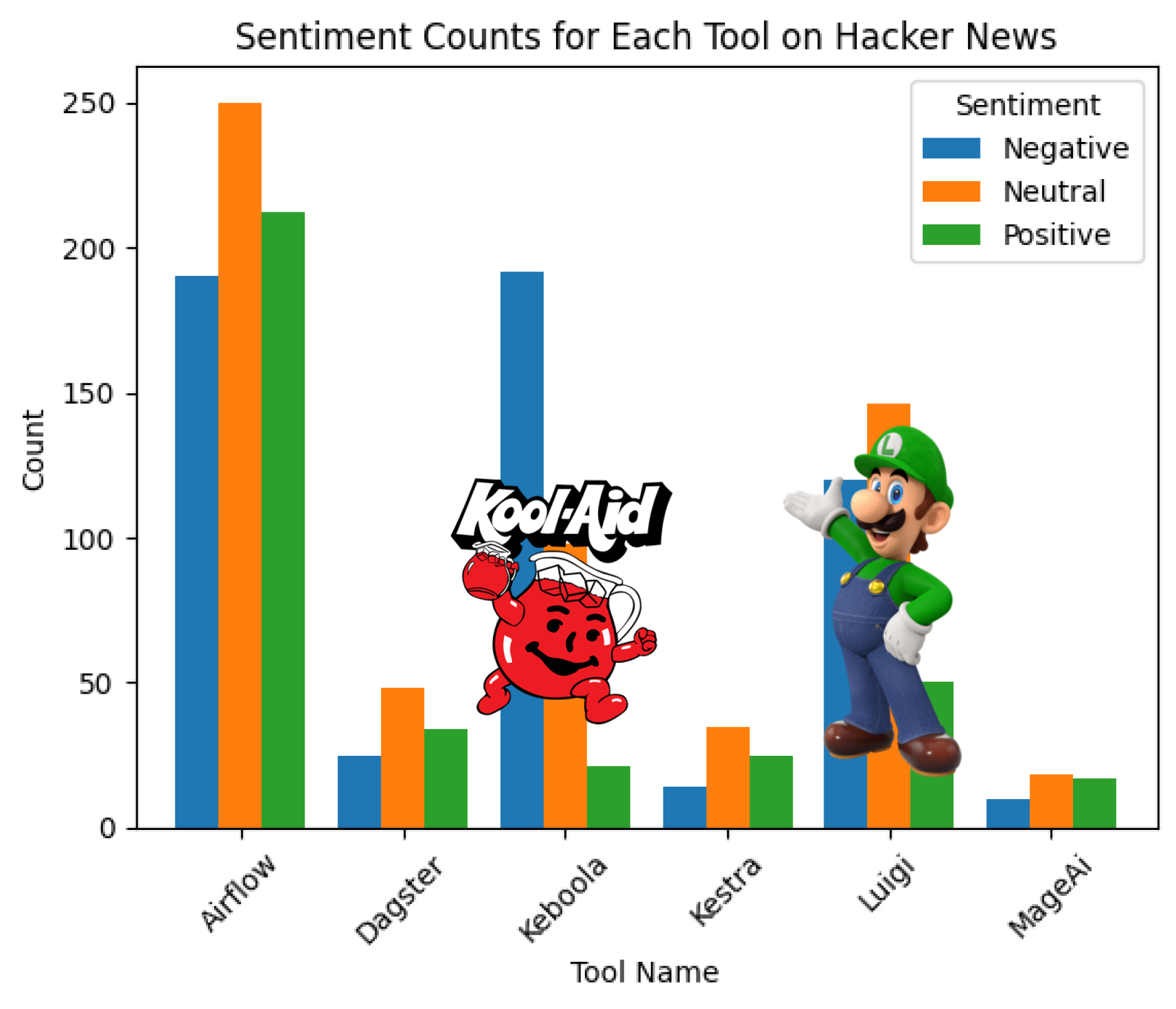
I understand if you're scratching your head at first glance, but let me clear things up. Remember those sneaky issues I mentioned with Keboola and Luigi earlier? Well, I've masked their charts with the respective “culprits”.
Now, onto the bars. Each trio of bars illustrates the count of negative, neutral, and positive comments on articles sourced from Hacker News that have at least one comment and were returned when searched for a specific orchestration tool, categorized accordingly by the specific data orchestration tool.
What's the big reveal? It seems like Hacker News readers tend to spread more positivity than negativity, though neutral comments hold their ground.
And, as is often the case with utilizing LLMs, this data should be taken with a grain of salt. It's more of a whimsical exploration than a rigorous analysis. However, if you take a peek behind Kool Aid and Luigi, it's intriguing to note that articles related to them seem to attract a disproportionate amount of negativity. 😂
IF YOU'RE STILL HERE
… and you're just dipping your toes into the world of data orchestration, don’t sweat it. It's totally normal if it doesn't immediately click for you. For beginners, it can be tricky to grasp because in small projects, there isn't always that immediate need for things to happen "automatically" - you build your pipeline, run it once, and then bask in the satisfaction of your results - just like I did in my project. However, if you start playing around with one of these tools now, it could make it much easier to work with them later on. So, don't hesitate to dive in and experiment!
… And hey, if you're a seasoned pro about to drop some knowledge bombs, feel free to go for it - because what doesn’t challenge us, doesn’t change us 🥹. (*Cries in Gen Z*)